ニューラルネットワークがわからないのはオンライン推定がイメージできないせいだ(その1) [理数系思いつき]
ニューラルネットワークをモノにするのにずいぶん苦労したが,いろいろぐぐってみて自分なりに考えてみたところ,ニューラルネットワークの解説の中でオンライン推定をハイライトしないものばかりであるためだとの理解に到達した。そこで今回は,オンライン推定についての解説を丁寧に行ったうえで,ニューラルネットワークの解説を行ってみたい。1 歪んだコインにおいて表が出る確率の推定について
手始めに簡単なところで,歪んだコインを投げて表が出る確率について考えてみよう。これまで学校で学んだやり方は,例えばコインを1000回投げてみたら表が300回出たので,表が出る確率は30%と推定しようというものではなかっただろうか。このように,十分な材料を集めてから行うタイプの推定はオフライン推定と呼ばれる。
オフライン推定の反対語はオンライン推定である。オンライン推定はオフライン推定と違って,十分な材料を集める前に推定を始めようとする。それはなぜかというと,1000回投げるまで待たなくても十分よい推定ができるとの期待からである。
数式で表してみよう。オフライン推定において表が出る確率の推定式は以下のとおり。
 はN回投げた結果に基づいた表が出る確率の推定値,
はN回投げた結果に基づいた表が出る確率の推定値,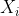 はi回目に投げた際に表ならば1,裏ならば0となるような値である。
はi回目に投げた際に表ならば1,裏ならば0となるような値である。
ところで,上の式から以下の式が導ける。
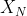 を用いて,N-1回投げた後の推定値
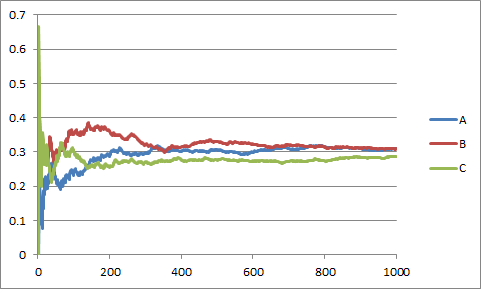
を用いて,N-1回投げた後の推定値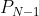 を,N回投げた後の推定値へと修正できるという式なのである。ここで重要なのは,N-1回目までの結果はすべてに情報として集約済みであり,あらためて立ち戻る必要がないことであり,1回投げるたびに推定値をジワジワと修正していくイメージがオンライン推定というわけである。正解が30%の場合で実際に試してみた。横軸:投げた回数,縦軸:推定値。回数が増える毎に正解に近づいていることがわかる。
を,N回投げた後の推定値へと修正できるという式なのである。ここで重要なのは,N-1回目までの結果はすべてに情報として集約済みであり,あらためて立ち戻る必要がないことであり,1回投げるたびに推定値をジワジワと修正していくイメージがオンライン推定というわけである。正解が30%の場合で実際に試してみた。横軸:投げた回数,縦軸:推定値。回数が増える毎に正解に近づいていることがわかる。
2 正解が途中で変わるケース
上ではオンライン推定について説明したが,これだけでは単なる計算のやり方の違いにすぎず,オンライン推定の強みを体感することができなかったかも知れない。以下では,強みを発揮するケースについて考えてみよう。そのために,上のオンライン推定式の1/Nをλに変更してみよう。
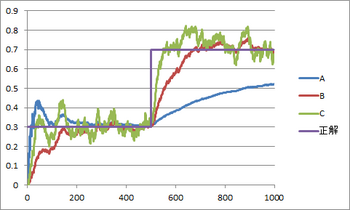
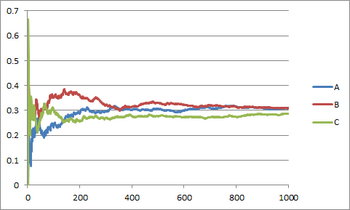
上のチャートは,途中でコインを交換したケースである。つまり,始めの500回では正解が30%だが,その後の500回では正解が70%へと急変するというものである。Aは従来のオンライン推定だが,正解の急変についていけてないことがわかる。一方,新しいオンライン推定であるB(λ=0.01)とC(λ=0.03)では,正解の急変にも頑張ってついていこうとしているのがわかる。
3 トレンドの反転はめずらしくない
従来のオンライン推定と新しいオンライン推定の最大の違いは,過去に対するこだわりの大小である。
従来のオンライン推定は過去の結果をすべて同じ重みで推定しようとしているため,正解が不変なケースにおいては回数の積み重ねによりどんどん正解に近づいていく力がある一方,途中で正解が変わるケースにおいては弱体化する。これに対して,新しいオンライン推定は概して正解への追随スピードは劣るものの,遠い過去へのこだわりが薄いため,途中で正解が変わるケースにおいても追随力が維持される。
それでは,結局どちらが優秀なのだろうか。答えは時と場合による。確率モデルのパラメータが安定的だと考えることが合理的な場合には従来のオンライン推定がよく,パラメータがときどき変わると考えることが合理的な場合には新しいオンライン推定がよい。誤解を恐れずに言えば,万物は流転するのであって,その意味では目をつぶって後者を愛用するというのも悪くないのではないか。
続きはまた今度。
手始めに簡単なところで,歪んだコインを投げて表が出る確率について考えてみよう。これまで学校で学んだやり方は,例えばコインを1000回投げてみたら表が300回出たので,表が出る確率は30%と推定しようというものではなかっただろうか。このように,十分な材料を集めてから行うタイプの推定はオフライン推定と呼ばれる。
オフライン推定の反対語はオンライン推定である。オンライン推定はオフライン推定と違って,十分な材料を集める前に推定を始めようとする。それはなぜかというと,1000回投げるまで待たなくても十分よい推定ができるとの期待からである。
数式で表してみよう。オフライン推定において表が出る確率の推定式は以下のとおり。
ところで,上の式から以下の式が導ける。
2 正解が途中で変わるケース
上ではオンライン推定について説明したが,これだけでは単なる計算のやり方の違いにすぎず,オンライン推定の強みを体感することができなかったかも知れない。以下では,強みを発揮するケースについて考えてみよう。そのために,上のオンライン推定式の1/Nをλに変更してみよう。
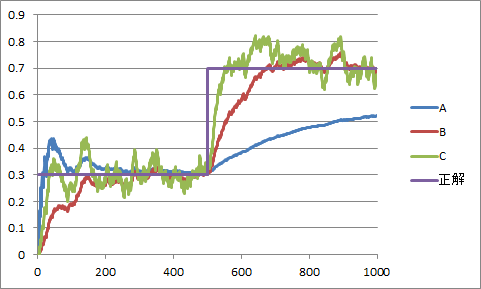
上のチャートは,途中でコインを交換したケースである。つまり,始めの500回では正解が30%だが,その後の500回では正解が70%へと急変するというものである。Aは従来のオンライン推定だが,正解の急変についていけてないことがわかる。一方,新しいオンライン推定であるB(λ=0.01)とC(λ=0.03)では,正解の急変にも頑張ってついていこうとしているのがわかる。
3 トレンドの反転はめずらしくない
従来のオンライン推定と新しいオンライン推定の最大の違いは,過去に対するこだわりの大小である。
従来のオンライン推定は過去の結果をすべて同じ重みで推定しようとしているため,正解が不変なケースにおいては回数の積み重ねによりどんどん正解に近づいていく力がある一方,途中で正解が変わるケースにおいては弱体化する。これに対して,新しいオンライン推定は概して正解への追随スピードは劣るものの,遠い過去へのこだわりが薄いため,途中で正解が変わるケースにおいても追随力が維持される。
それでは,結局どちらが優秀なのだろうか。答えは時と場合による。確率モデルのパラメータが安定的だと考えることが合理的な場合には従来のオンライン推定がよく,パラメータがときどき変わると考えることが合理的な場合には新しいオンライン推定がよい。誤解を恐れずに言えば,万物は流転するのであって,その意味では目をつぶって後者を愛用するというのも悪くないのではないか。
続きはまた今度。
2016-02-08 21:50
nice!(0)
コメント(0)
トラックバック(0)




コメント 0